Uwe Rienäcker |
|
Videokompression durch schwellwertgesteuerte Kodierung von
Differenzbildern der DCT Koeffizienten
|
|
Zusammenfassung |
|
In diesem Dokument wird ein Ansatz zur zusätzlichen
Kompression bei der Aufzeichnung von Motion JPEG Videodaten durch
schwellwertgesteuerte Kodierung von Differenzen der DCT Koeffizienten
aufeinanderfolgender Frames beschrieben. Ausgehend von einem
Referenzbild werden alle nachfolgenden Frames als Differenz der DCT
Koeffizienten zum jeweils vorhergehenden Referenzbild kodiert. Es werden
jeweils nur die Blöcke kodiert, deren Koeffizienten eine
signifikante Differenz zum aktuellen Referenzbild aufweisen. Eine
Kompensation von Bewegungen, vergleichbar mit der der MPEG Kompression,
wird nicht vorgenommen, da diese auf das durch die DCT Blöcke
festgelegte Raster eingeschränkt wäre. Durch Beschränkung
aufwendiger Operationen auf ein Minimum ist die Kodierung mit geringen
Anforderungen an die Hardware echtzeitfähig und kann in
Ergänzung zur selektiven
Aufzeichnung verwendet werden. Experimentelle
Ergebnisse zeigen, daß eine durchschnittliche Reduktion der Daten
auf ein Zehntel des ursprünglichen Volumens ohne sichtbare Verluste
an Qualität im Vergleich zum Original erreichbar ist.
|
|
Hintergrund |
|
Die selektive
Aufzeichnung von Videodaten hat das
Datenvolumen im beschriebenen Versuch auf 1/50 reduziert. Ein
Szenenwechsel ändert die Verhältnisse. Die Ereignisse von
Interesse treten häufiger auf. Die Datenmengen wachsen
proportional. Die JPEG und damit auch die Motion JPEG Kompression
erreicht bei akzeptabler Qualität eine Kompressionsrate von 100:1.
Mit deutlichen Einbußen ist auch 200:1 erreichbar. Ein Frame der
Auflösung 320x240 hat durchschnittlich 20 KByte Größe.
Bei einer Aufzeichnungsgeschwindigkeit von 15 Frames je Sekunde fallen
300 KByte je Sekunde an. Das entspricht 1,4 MBit je Sekunde. Für
eine Auflösung von 320x240 Bildpunkten sind diese Datenmengen
entschieden zu viel. Die Bitrate je Pixel ist bei deutlich geringerer
Qualität ungefähr äquivalent zu einer herkömmlichen
DVD Aufzeichnung im XP Modus.
|
|
In den seltendsten Fällen ist ein Anteil von mehr als die
Hälfte der Bildfläche veränderlich. Das gilt insbesondere
für stationäre Videoaufzeichnungen. Durchschnittlich ist
hierbei kaum mehr als ein Viertel des Bildausschnitts in Bewegung. Die
von den Bewegungen verursachten Veränderungen sind im Mittel
geringer als die Amplitude des Signals selbst. Durch eine Reduzierung
der redundanten Informationen kann das Datenvolumen erheblich verringert
werden. Dieses wird beispielsweise durch die MPEG Kodierung erreicht.
Diese erhält im Unterschied zu dem in diesem Dokument beschriebenen
Verfahren die Rohdaten pixelorientiert. Liegen die Videodaten jedoch
bereits in komprimierter Form vor, müßten sie für die
MPEG Kodierung erst vollständig dekodiert werden, um dann wieder
kodiert zu werden. Durch Differenzbildung der DCT Koeffizienten kann ein
wesentlicher Teil zeitaufwendiger Operationen eingespart werden, ohne
für den vorgesehenen Zweck schlechtere Ergebnisse als die einer
MPEG Kodierung zu erzielen. Auf eine aufwendige Kompensation von
Bewegungen muß bei diesem Verfahren allerdings wegen des
durch die DCT Blöcke gegebenen Rasters verzichtet werden.
|
|
Verfahrensbeschreibung |
Rohdatenformat |
|
Das Verfahren ist für eine weitere Kodierung von Videodaten im
Motion JPEG Format, wie es beispielsweise von verschiedenen
Netzwerkkameras geliefert wird, vorgesehen. Das Verfahren selbst nimmt
weder eine DCT noch eine IDCT Kodierung vor. Es verwendet die
unveränderten DCT Koeffizienten und Kompressionseinstellungen der
Datenquelle. Diese dürfen sich im Verlauf einer Aufzeichnung nicht
ändern.
|
Synchronisation SOI-EOI |
|
Der Vollständigkeit halber wird die Synchronisation der
bildbegrenzenden Marker SOI, start of image und EOI, end of image, als
vorverarbeitende Komponente erwähnt. Durch diese Synchronisation
werden während der Aufzeichnung desöfteren auftretende
unvollständige oder fehlerhafte Einzelbilder gefiltert. Dies
sichert einen fehlerfreien Datenstrom für die nachfolgende
Verarbeitung.
|
Referenzbild und Kodierungstabellen |
|
Das initiale Referenzbild sowie die JPEG Kodierungsparameter der
Datenquelle werden in Form des ersten Bildes der Aufzeichnung
unverändert übernommen. Auf dieses als JPEG gespeicherte
Einzelbild beziehen sich die nachfolgend kodierten Veränderungen.
Die JPEG Parameter verändern sich während der weiteren
Aufzeichnung nicht. Die JPEG Kompressionsrate wird somit von der
Datenquelle festgelegt.
Unmittelbar im Anschluß an das Referenzbild werden die für
die Kodierung der Differenzen der DCT Koeffizienten benötigten
Huffmann Tabellen gespeichert. Für die Kodierung von DC- und AC
Koeffizienten getrennt nach Luminanzkanal und Chrominanzkanälen
werden unterschiedliche Huffmann Tabellen verwendet. Diese werden aus
zuvor ermittelten Histogrammen für den jeweiligen Koeffiziententyp
berechnet und sind w�hrend der gesamten Aufzeichnung
unveränderlich.
|
Dekodierung der Quelldaten |
|
Zur Schaffung der Voraussetzungen für die Berechnung und Kodierung
der Differenzen der DCT Koeffizienten werden die Quelldaten bis auf die
Ebene der DCT Koeffizienten dekodiert und diese dequantisiert. Die
Dequantisierung selbst wird dabei ausschließlich für die
Unabhängigkeit der Schwellwertoperationen von der Kompression der
Quelldaten benötigt.
|
Differenzbildung Schwellwertoperation |
|
Für jeden DCT Block wird anhand des Vergleichs der Differenz
zwischen den dequantisierten DCT Koeffizienten des aktuellen und des
Referenzbildes mit einem Schwellwert entschieden, ob dieser Block im
aktuellen Frame kodiert werden soll. Mit dem eingestellten
Schwellwert wird die Empfindlichkeit des Systems gegenüber
Veränderungen und damit die Qualität der resultierenden
Aufzeichnung beeinflußt. Die Auswahl der zum Vergleich
herangezogenen DCT Koeffizienten ist variabel einstellbar. Die für
die Kodierung ausgewählten Blöcke werden zu rechteckigen
Bereichen zusammengefaßt, wobei die resultierende Kodelänge
als Ziel eines Optimierungsschrittes betrachtet wird. Es wird ein
Kompromiß zwischen zusätzlicher Informationslänge
für Koordinaten der Rechtecke und der Kodelänge der nicht zu
übertragenden Blöcke ohne Differenz zum Referenzbild
eingegangen. Je größer die Rechtecke sind desto mehr nicht zu
übertragende Blöcke können sie enthalten. Je kleiner die
Rechtecke sind desto mehr Information wird für die Koordinaten
der Rechtecke im Vergleich zu ihrer Gesamtfläche benötigt.
Die Optimierung wird durch die Teilung von Ausschnitten der Rechtecke
mit hoher Dichte nicht zu übertragender Blöcke erreicht.
|
Differenzbildkodierung |
|
In einem abschließenden Schritt werden die Differenzen der
quantisierten DCT Koeffizienten aller ausgewählten Blöcke
gleich dem Prinzip der JPEG Kodierung zunächst in die ZigZag
Reihenfolge umsortiert und in VLC Symbolfolgen umgewandelt. Blöcke
innerhalb zusammengefaßter rechteckiger Bereiche, die nicht
für die Kodierung ausgewählt wurden, werden wie Blöcke
ohne Differenz zum Referenzbild kodiert. Die entstandenen VLC
Symbolfolgen werden mittels Huffmann Kodierung komprimiert. Für
alle kodierten Blöcke wird das Referenzbild angepaßt, damit
eine kodierte Differenz innerhalb eines Frames nicht ein weiteres Mal
kodiert wird. Mehrfachkodierungen wären sonst durch räumliche
Überlagerung der Rechtecke möglich. Andererseits müssen
Differenzen unterhalb des Schwellwerts erhalten bleiben, da diese sich
im Verlauf der Aufzeichnung vergrößern und damit die Schwelle
überschreiten könnten. Handelt es sich bei den geringen
Differenzen nur um kurzfristige kleinere Veränderungen, werden die
Informationen für diese bei der Kodierung eingespart. In jedem Fall
wird durch die selektive Anpassung des Referenzbildes sichergestellt,
daß dieses zu jeder Zeit identisch mit dem letzten aus der
bisherigen Kodierung resultierenden Bild ist.
|
Zusatzinformationen |
|
Zusätzlich zu den Bildinhalten wird der Startzeitpunkt der
Aufzeichnung und die seit der jeweils letzten Kodierung eines Frames
vergangene Zeit in den Datenstrom eingefügt. Auf synchronisierende
Frames wird im derzeitigen Implementationsstand noch verzichtet. Damit
ist nur eine sequentielle Dekodierung der resultierenden Aufzeichnung
mit geringer Fehlertoleranz möglich. Praktisch bereitet aber die
Navigation in Aufzeichnungen von mehreren Stunden keine Schwierigkeiten.
|
|
Das folgende Bild zeigt die schematische Darstellung der
schwellwertgesteuerten Differenzbildkodierung.
|
|
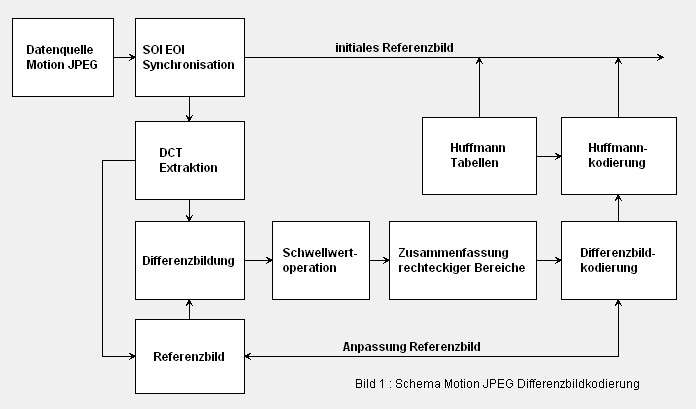
|
|
Kombination mit selektiver Aufzeichnung |
|
In Kombination mit der selektiven
Aufzeichnung bestimmt das Ergebnis der
qualitativen Bewertung einer Szene, ob der Frame kodiert wird oder
nicht. Die Bewertung kann dabei eine reine Bewegungserkennung oder
diese in Kombination mit der Klassifikation der bewegten Objekte sein.
Nicht oder negativ klassifizierte Frames werden nicht kodiert. Das
Referenzbild wird für diese Frames nicht aktualisiert, damit bei
der nächst folgenden Klassifizierung die vollständige
Differenz zum zuletzt kodierten Frame berücksichtigt wird. In
längeren Pausen ohne Klassifizierung werden in
regelmäßigen Abständen Frames zur zeitlichen
Synchronisation der Aufzeichnung kodiert und das Referenzbild
angepaßt.
|
|
Experimentelle Ergebnisse |
Kompressionsraten |
|
Im Vergleich zur Motion JPEG Kompression mit einer ursprünglichen
Datenreduktion von ca. 100:1 wurden durch die Differenzbildkodierung
bei unterschiedlicher Qualität die in der folgenden Tabelle
aufgeführten zusätzlichen Kompressionsraten erzielt. Die
Qualität beschreibt die Qualität im Verhältnis zur
Original Motion JPEG Aufzeichnung. Die Kompressionsraten sind
Durchschnittswerte von 5 verschiedenen stationären
Tagesaufzeichnungen. Die erzielten Kompressionsraten und die daraus
resultierende Qualität sind darüber hinaus von
den Helligkeits- und Kontrastverhältnissen abhängig.
|
| Stufe |
Qualität |
Kompression |
| 1 |
Verlustfrei |
4:1 |
| 2 |
geringe Verluste |
8:1 |
| 3 |
sichtbare Verluste |
16:1 |
| 4 |
deutliche Verluste |
18:1 |
| 5 |
sehr deutliche Verluste |
19:1 |
| 6 |
maximal akzeptable Verluste |
20:1 |
|
|
Im Vergleich zu stationären Aufzeichnungen, bei denen sich im
Durchschnitt ein Großteil des Hintergrunds nicht bewegt, fallen
die Kompressionsraten beispielsweise bei der Kodierung eines Spielfilms
deutlich geringer aus. Gute Qualität wird mit einer Rate von 2:1
erreicht. Bei einer Kompressionsrate von 5:1 ist die Qualität noch
akzeptabel.
|
Geschwindigkeit |
|
Die Geschwindigkeit der Videoanalyse ist unabhängig von der
Kompressionsrate der Datenquelle. Dagegen wächst der Zeitbedarf der
Diffferenzkodierung mit höherer Qualität durch einen kleineren
Schwellwert, da mehr Blöcke zu kodieren sind. In der höchsten
Qualitätsstufe können auf einem P133 PC bis maximal 10 Bilder
der Auflösung 320x240 je Sekunde kodiert und aufgezeichnet werden.
Mit der zweithöchsten Stufe steigt die Verarbeitungsgeschwindigkeit
auf 15 Bilder je Sekunde und erreicht maximal 20 Bilder je Sekunde in
der niedrigsten Qualitätsstufe. Die Integration in das Schema der
selektiven Aufzeichnung veringerte die Geschwindigkeit nur unwesentlich.
|
|
Schlußfolgerungen |
|
Die nachträgliche Kompression von Motion JPEG Videodaten durch
Differenzbildkodierung bewirkt insbesondere im Kontext stationärer
Aufzeichnungen eine deutliche Datenreduktion. Die Einsparung
zeitaufwendiger Operationen ermöglicht einen Echtzeitbetrieb mit
geringen Anforderungen an die Hardware. Eine Vielzahl mit der
selektiven Aufzeichnung gemeinsamer Verarbeitungsschritte vereinfacht
eine Integration dieser in das Kompressionsverfahren ohne wesentliche
Verluste an Geschwindigkeit. Für Spielfilme und ähnliche
Videodaten ist das Verfahren wegen der fehlenden Bewegungskompensation
weniger geeignet. Bewegungen können nur im Raster der DCT
Blöcke erfaßt werden. Versuche der Kompensation von
Bewegungen auf Blockebene lieferten keine dem Aufwand angemessene
Reduktion der Datenmengen.
Durch das Fehlen synchronisierender Frames ist der resultierende
Datenstrom bisher nur sequentiell dekodierbar und nicht fehlertolerant.
In der Praxis hat dieser Nachteil bisher keine Auswirkungen gezeigt.
Alle bisherigen Aufzeichnungen waren fehlerfrei dekodierbar. Eine
höhere Fehlertoleranz z.B. für die Übertragung über
unsichere Medien kann durch Einfügen vollständiger Frames zur
Synchronisation in den Datenstrom erreicht werden. Dadurch wird die
erzielte Kompressionsrate wieder verringert.
|